Enterprise design
Introduction
This section provides guidance on deploying Veeam in larger-scale environments which for this document will start at 5000 virtual machines.
Large scale Veeam Backup & Replication deployments
There’s no hard limit of VM’s number in a single Veeam Backup & Replication instance. However, the recommendation is to keep it under 10,000 VMs per instance. At the same time installations with 18000 VMs per instance are seen in the field as well.
When scaling in Veeam Backup server to the limit (10,000-18,000 VMs) following official requirements — you can face the case when size is almost equal or even over the amount of resources of your ESXi hosts.
In addition, your environment can bring additional limitations — as there are many variables not least the available resources within the Hypervisor.
There are basic approaches to deal with this situation. For both options virtual is the recommended deployment. (more details here).
-
Scale-in by a gradual increase of provisioned resources.
As most deployments on large scale are not instantly coming to a maximum - consider a gradual increase of resources.
The approximate amount of required resources can be calculated using Veeam Size Estimation Tool
However, official recommendations are quite conservative and real results can vary on a large scale.
Still biggest cons of the approach:
- chance of VBR server requirements will be close or even over the size of the ESXi host
- single point of failure -
Scale-out (split jobs between servers)
The core idea is to have multiple Veeam Backup & Replication servers running backups for the same infrastructure(even the same vCenter). For centralized monitoring, management and restore platform, Veeam Enterprise manager should be used.
In this scenario, it’s recommended to start with a single Veeam Backup & Replication deployment and increase the number of Veeam Backup & Replication servers if required. That will prevent initial overprovisioning and operational complications related to the increased overhead of multiple servers.
The biggest con of the approach is the requirement of dedicated proxies and repositories per Veeam Backup & Replication. More details below.
The choice between the two options is ultimately up to you how you prefer to scale the environment. However, many people have success by combining both.
High-level example of Scale-Out Design:
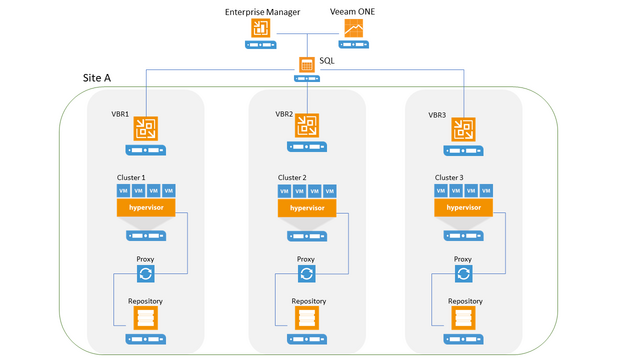
When do I need to choose?
As mentioned previously this is highly dependent on available resources in the hypervisor and amount of capacity being backed up. However, we have found that at 3,500-5,000+ VMs these options start to need to be considered.
Please use the best practice calculations to estimate the resource requirements for Veeam Backup & Replication and SQL.
Protection domains
Using the scale-out method, the environment is split down into smaller protection domains which also overlap with failure domains. These have the advantage of:
Increased security
Splitting the Veeam Backup & Replication servers into smaller environments while using security best practices, means that a breach on one server will potentially affect less of the overall Veeam deployment.
Reduction in restore times
At scale, Veeam Backup & Replication can take some time to rebuild from a configuration backup, though this is still usually measured in minutes. However, by splitting the Veeam Backup & Replication servers the restore times for an individual server will be reduced.
Configuration Database
Note that it’s expected that Veeam Backup & Replication configuration for 500+ VM will require SQL DB > 10GB. That’s said, a licensed edition of the SQL server will be required.
As with the Veeam Backup & Replication server, the configuration database will require significant resources though likely at a lower rate than the Veeam Backup & Replication. However, like with the Veeam Backup & Replication server, there will be a point a decision will need to be taken on scale-up or out.
Many customers with large environments may have an existing SQL server(s) that could be used. If not, the options are to either include an instance of SQL with each Veeam Backup & Replication or to create a centralized server. Similar questions to the scaling of Veeam Backup & Replication need to be asked, though the additional cost of SQL licenses may likely be a defining factor.
Note: the connection between Veeam Backup & Replication and the configuration DB is latency-sensitive. The best practice is to use a direct connection without WAN traffic.
If Veeam ONE is in-scope then a dedicated server is likely the best option as the database requirements can be quite significant at this scale. See the Veeam ONE DB calculator.
Proxy and repositories
Each Veeam Backup & Replication instance should be allocated dedicated proxy and repository resources. This is required because each Veeam Backup & Replication instance will be independent and therefore not aware of another instances’ resource scheduling (e.g. allocation of slots for a proxy or repository).
Where possible, natural divides in the virtual architecture should be followed. At the most basic level, this could be at the site level then down to cluster level if there is more than one in the environment.
When using Backup from Storage Snapshots (BfSS) there will be an increase in SAN network connectivity as each proxy will require its connections. Also, when configuring jobs, consideration will need to be made to not have jobs that target the same datastore at the same time. In this case the jobs schedules should be factored into the planning.
Centralising management and monitoring
In a scale-out approach, it will be important to centralize as much of the operations and monitoring as possible. Using Enterprise Manager is essential for centralizing and delegating many of the operations.
Veeam ONE is highly recommended as it will remove a significant amount of the operational overheads in monitoring and reporting on a solution of this scale.