Dell EMC Data Domain
Data Domain Advanced Scalability
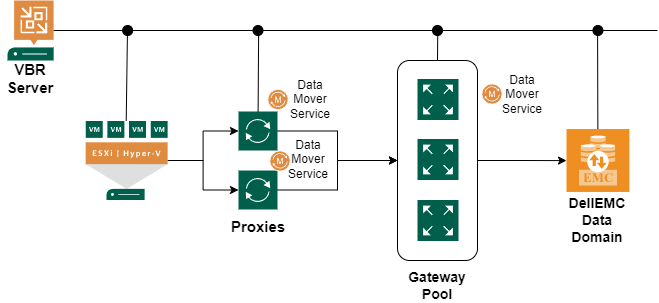
Prior to VBR v12 only a single gateway could be assigned to a Data Domain repository. This meant that to parallelize the backup traffic, multiple repositories had to be created and assigned to different gateways.
Since v12 you can now configure multiple gateways to Data Domain in what is known as a Gateway pool which allows for far easier parallelization of backup traffic. This is different from the pre-v12 best practice where the advice was to create multiple repositories and assign them to different gateways which also had the proxy role.
The workloads will be spread across the gateways in the pool to balance the load. You can also adjust what gateway(s) are used for a Data Domain repository by modifying the Gateway selection in the Data Domain repository properties. Link
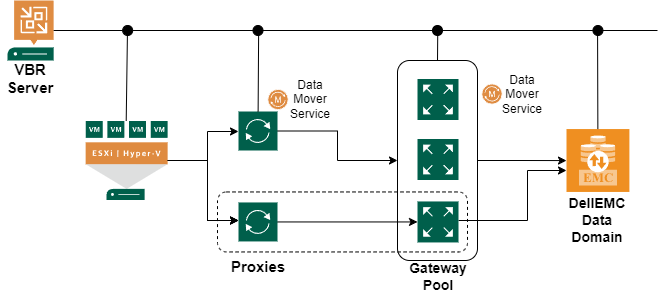
Note that if the gateway server is also assigned the proxy role then the workloads assigned to that proxy/gateway will be sent to the Data Domain directly. So it will not distribute the traffic to other gateways in the pool.
NAS Backup to Data Domain
Data Domain can be used as a:
- Backup Repository
- Archive Repository
- Secondary Repository
It has been observed that if the data type being backed up is a good candidate for deduplication, then the Veeam backups will be as well. Non-deduplication friendly data types, such as compressed files, will not deduplicate well on the Data Domain.
Using deduplication on the NAS backups can significantly reduce the capacity required compared to using a standard repository. In particular when there are multiple shares or the retention of the data is high e.g. months or years.
NAS Backup Metadata extent
It is highly recommended when using Dell EMC Data Domain that the NAS metadata is placed on a separate SSD based extent outside of the Data Domain.
The reason for this is the high performance demands on the metadata during NAS backups and the relatively low performance of the Data Domain.
You can move the metadata extent by using the Set-VBRRepositoryExtent cmdlet.
Example from Help Center:
Set-VBRRepositoryExtent –Extent “NAS Backup Repository on SSD” -Metadata
Set-VBRRepositoryExtent –Extent “Backup Repository 1” –Data
See link in the references for more information.
References
- Alliance Partner Integrations & Qualifications - DellEMC Deduplication Target
- Helpcenter - Dell EMC Data Domain
- Knowledge Base - Deduplication Appliance Best Practices
- NAS Storage Repositories
- Enterprise Plugs-in Guide
- Scale-Out Repository with Extents in Metadata and Data Roles