Overview
VBAZ uses the following components for the backup process:
- A backup appliance to control backup operations via a service bus and workers
- A service bus to communicate with workers
- Pools of workers used to run backup operations that send data to repositories
- A storage account used for worker provisioning
- A storage account used as a backup repository
This guide is intended to provide best practices around sizing, deploying and using VBAZ, and assumes you have already read the Veeam Backup for Microsoft Azure documentation.
How backup works
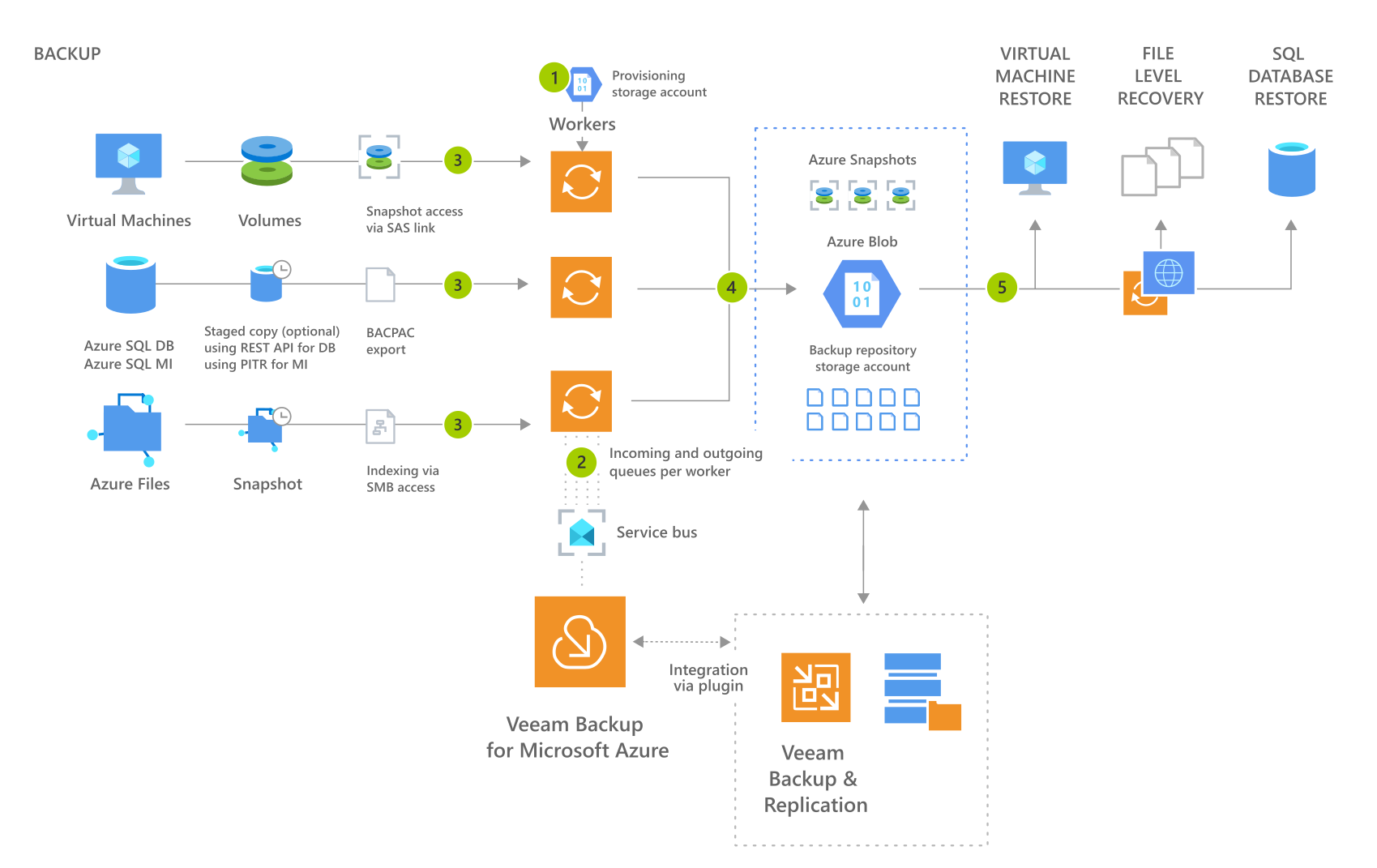
-
Workers are created to form a worker pool, with the correct networking in-place. Existing workers are re-used but may be shut down when not active. Once workers are deployed binaries are installed using the packages stored on the dedicated storage account used for provisioning. This dedicated storage account is provisioned automatically upon initial install.
-
Once deployed workers communicate via a service bus, there is an ingoing and outgoing queue per worker created. This service bus is provisioned automatically upon initial install.
-
The worker service starts processing the backup at source. Workers can also be used to manage repository operations and data tiering. Job policy settings are processed, with one worker per virtual machine or SQL database:
for Virtual Machines
a. A pre-freeze script is run inside the VM using the Azure VM agent on Windows or waagent on Linux (optional).
b. A VM snapshot is created by the appliance. Snapshots for managed virtual disks are saved to the resource group where the Azure VM belongs, snapshots for unmanaged virtual disks are saved to the storage account where the Azure VM resides.
c. A post-thaw script is run inside the VM using the Azure VM agent on Windows or waagent on Linux (optional).
d. Snapshots are read from the worker using a temporary SAS link. During an incremental backup sessions workers use changed block tracking (CBT) to compare the newest snapshot to the previous one.
e. Data is offloaded by the worker to the repository storage account.
for Azure SQL
a. The worker tests the connection to the Azure SQL DB or Azure SQL MI instance (or staging location if used).
b. The appliance issues a command to create a staged copy for the Azure SQL DB or Azure SQL MI database (optional).
c. Azure SQL BACPAC export is started, and its contents are processed.
d. Data is offloaded by the worker to the backup repository storage account.
for Azure Files
a. The appliance issues a command to create a snapshot of the Azure Files share.
b. For indexing, a paid edition feature, a worker tests SMB connectivity to the share and enumerates its contents.
c. Compressed file index is offloaded by the worker to the Veeam Backup for Azure Appliance (/var/lib/veeam/fs_indices).
-
Based on worker pool settings, workers can be stopped and removed if over the minimum worker count configured. Workers can be re-used as part of the same job policy run or the next time a job runs.
-
VMs, files, and BACPAC exports can be restored by using the source snapshots if applicable or Azure Blob repository data. For File Level Recovery a helper is used.
Restore Operations
In order to restore over an existing disk, the original VM will be de-allocated, a temporary resource group with a new disk is created, the new disk is swapped out for the original disk, and the original disk is removed. This newly restored disk is then moved to the original resource group and the temporary resource group is removed.
In order to restore from a managed Azure VM snapshot in one region to another region, data is downloaded to this via a SAS link and a new managed disk is created from this and the temporary storage account is deleted.
Note that for unmanaged Azure VMs it is possible to restore snapshots and backup data as unmanaged VMs or to change these into managed VMs upon restore. In that case however we copy blob data by URI instead. A restored VM disk can increase in price due to the difference between managed and unmanaged VM disk pricing.
Networking
Note that VBAZ deploys with a public IP address by default, but after deploying you can remove this. The only feature affected by this is File Level Recovery. Veeam Backup for Azure v4 comes with logic to handle private networking, including support for premium service bus which has a virtual network endpoint and will work with private endpoints.
Service providers
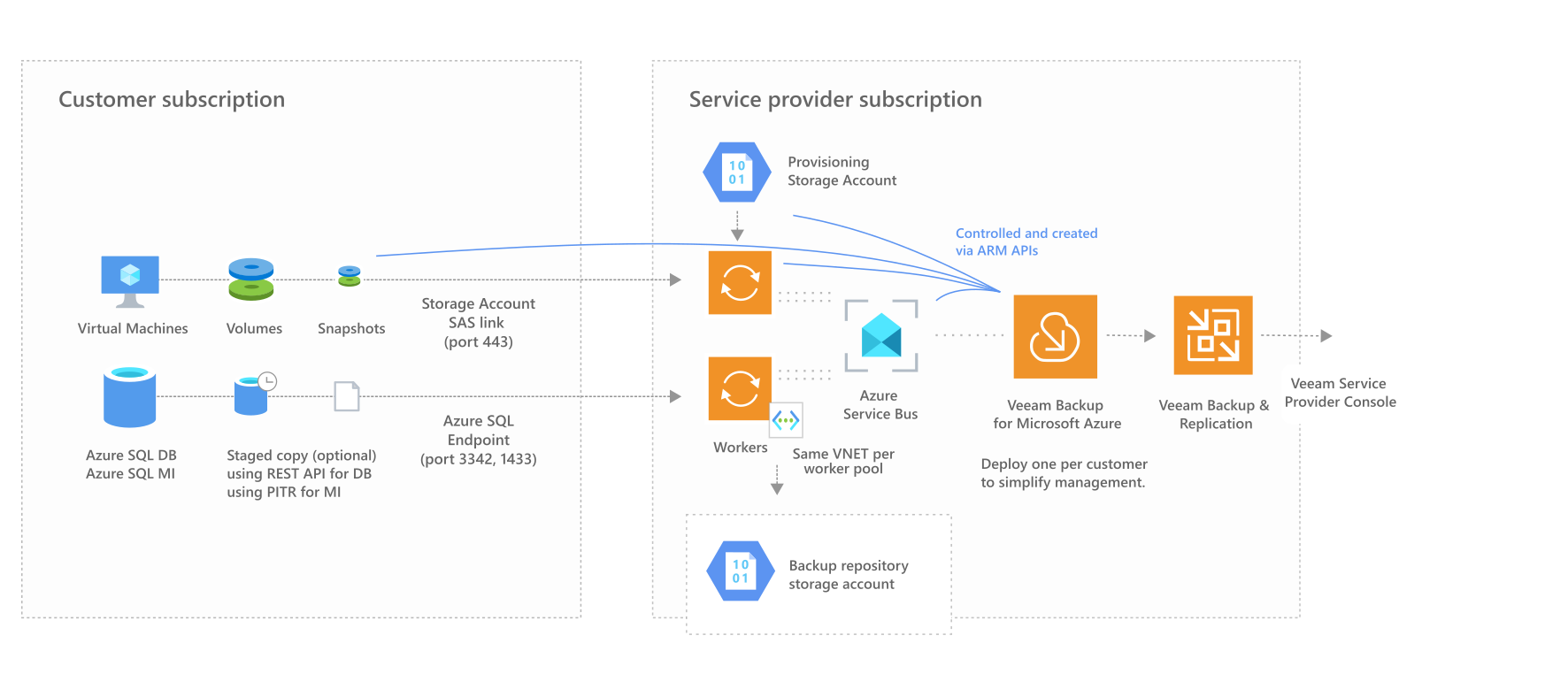
You can connect multiple Veeam Backup for Azure (VBAZ) instances to Veeam Backup & Replication (VBR). Ideally one VBAZ is deployed per customer, or more depending on scale. This in turn, can be managed with Cloud Connect and the Veeam Service Provider Console (VSPC).
Workers and resources will be deployed in in the same subscription and resource group as VBAZ. If you desire to have these exist in the customer subscription, deploy VBAZ in the customer subscription and everything will work as if deployed per individual customer, you can then link up VBR and the VSPC console to fullfill service provider functions.
You can use one VBAZ instance to back up more than one subscription in multiple Azure Active Directory Tenants. This can be configured by adding an account that has access to multiple subscriptions and tenants, or by adding multiple accounts. While this is useful to segment resources, from a management and scaling perspective it is still wise to deploy one VBAZ per customer.
It is also possible to use Azure Lighthouse within Veeam Backup for Azure, but due to complexity we find most end up using the multi-subscription and multi-tenant support without this.
You can put the backup repository storage account in a subscription separate from both the customer and service provider subscriptions as long as you have access. When using Azure Lighthouse the backup repository cannot be in the Lighthouse tenant subscription.