



Veeam Backup & Replication Best Practice Guide
Enterprise Plug-Ins
Veeam Enterprise Plug-Ins provide application level backup capabilities for enterprise databases like Oracle, HANA and MS-SQL. As the nature of Plug-In backups differs from the usual image-based VM and Agent backups, there are special design considerations necessary.
Some of the following protection requirements are typical to enterprise database environments and make clear why these backups are different to daily machine image backups:
- Daily active full backup might be the normal case for fastest recovery
- Compression is disabled to achieve lowest RTO
- Log backups needs to be transferred multiple times per hour (e.g. every 15 minutes)
- A backup downtime of some hours might cause production systems to fail because transaction log locations can run out of space
- No or even just slow backups create alerts on application level for business critical applications like SAP
The best practices on this page adhere to all types of Veeam Enterprise Plug-In backups, please check the respective operate sections for details on each application.
Enterprise Plug-In best practice summary
- Consider the shared responsibility between database administrators and Veeam backup administrators
- Create a separate Scale-Out Backup Repository in Performance Mode.
Configure unlimited task slots and size 1 CPU core/1 GB RAM per 5 concurrently used backup channels. - (optional) Separate all Plug-In backups to a dedicated backup server
- Use the force-delete option as garbage collector after native app retention in unmanged mode
- Tune the Windows network settings in larger environments to prevent TCP port exhaustion
- Avoid OS TCP timeouts by using Preferred Network Rules or TCP deny/unreachable answers
Shared responsibility
Depending on the operation mode, the responsibility for the backups is more or less shared between the application owner (Database Administrator, DBA) and the backup admin.
When application Plug-Ins are unmanaged, the DBA operates the backup & restore procedures, including own scheduling from the DB native tooling (e.g. Oracle RMAN, SAP HANA Studio or SQL Management Studio). The Veeam administrator provides repositories and transparent backend services like backup copies without being aware of when and what type of backups will arrive from the database servers.
Even in managed mode, when the Veeam administrator creates application policies to protect databases which include the scheduling, the DBAs can still run backup & restore operations from the native database tools at their disposal.
Having awareness of this shared model and the responsibilities coming along with it, is crucial to avoid situations like overload of the infrastructure which can lead to protection gaps.
Workload Separation
As described above, the requirements for Plug-In backups can differ a lot from image based backups and combining both worlds within a single backup design can be challenging. It often makes sense to separate the application Plug-In backups from other types of workloads. While some of these separation topics are very strong best practices, others require more careful consideration.
Separate Repository
This is strongly recommended.
Create a separate Scale-Out Backup Repository in Performance Mode for Plug-In backups. This simplifies dedicated settings for access permissions for Plug-In users and performance mode allows higher overall performance by distributing Plug-In files via round robin on the available extents.
For the single extents, configure either no task-slot limits or a high enough value to handle all scenarios. Plug-In backups are more sensible to task-slot congestion than usual backups. While backup processes will wait for the availability of free task slots in case of congestion, the timeout values on the application layer (databases) are often very low and backups will run into warnings or even errors when taking too long. To not overload the backup infrastructure, manage the load on the source side (database Plug-In) and do not use too many parallel backup channels (e.g. manage the load by distributing backups over the day/week).
Do consider backup copy jobs of the application backups when sizing task slots. If you have a task slot limit configured on the primary repository, configure a low enough value on the target repository to avoid congestion of the primary repository which might break primary backups.
To avoid very long rescan times on repositories, consider to reduce the number of Plug-In backups targeting a single repository, e.g. by configuring separate logical repositories for production, QA and dev environments. Rescans lock the repository for the scan time and such can prevent log backups from being written.
Repository sizing
As the repository workload for Plug-In backups is less than for machine backups you can run more task slots per CPU core or GB of RAM.
Repo resources = 1 CPU Core + 1 GB of RAM per 5 concurrently used backup/restore channels
As a best practice add an additional 15% of memory on each repository server to have more headroom.
You can also check the Veeam Help Center for CPU and memory sizing requirements for Plug-In backups, e.g. for Veeam Plug-In for SAP HANA.
Example
You run 3 parallel full backups with a parallelization of 4 (e.g. 4 RMAN channels each) and have 7 more systems shipping logs with 1 channel.
# Task Slots for full backups
3 Systems * 4 Channels = 12 Channels
# Task slots for archive logs
7 Systems * 1 Channel = 7 Channels
# Resources
(12 + 7) Channels / 5 Channels per 1CPU/1GB = 4 CPU cores & 4GB RAM
# Adding 15% headroom on Memory
4 CPU & (4 GB RAM * 1.15 ) = 4 CPU & 5 GB RAM
This is a worst case example assuming all logs will be shipped in parallel and sessions cannot wait at all. In reality logs would be shipped in intervals, e.g. every 15 minutes, and shipping will not take too much time (depending on the size of the logs), e.g. 1 minute. This means, that not all systems will ship at the very same time and not many sessions will run in parallel as the sessions only run for a short time.
In larger deployments calculating with the worst case might not be resource efficient. While in the above example the worst case means 2 CPU cores and 2GB of memory, the very same case with a 100 DB systems means 20 CPU cores and 20GB of memory (both excluding the 15% headroom).
It is recommended to start with a worst case calculation for resources, but if the worst case resource calculation is not bearable the above thoughts about log parallelism can be taken into account.
Also consider that with the recommended setting of unlimited task slots on the repository parallel incoming log sessions would still be running in parallel even if the repository was sized for less parallel sessions. That means these sessions might be a little slower, so e.g. instead of a log backup session taking 1 minute it might take 1.5 or 2 minutes, but it will still run. In operations it is important to monitor the load of the repository and adjust resources when discovering high load due to many parallel sessions and also monitor the duration of the backup sessions.
Separate backup server
This can be considered based on the size of the infrastructure.
As Plug-In backups are more sensible to backup infrastructure downtimes (e.g. due to maintenance) creating a completely separated VBR server is often a good idea in large or critical environments. The own VBR should obviously come with it’s own infrastrcuture, especially own repository resources. To provide a centralized holistic view on multiple VBR installations, the Enterprise Manager can be used on top of these separated instances.
Retention
When running unmanaged Plug-Ins, the retention of backups needs to be taken care of from the native backup application, e.g. Oracle RMAN. Make sure that any kind of retention is not only deleting the backup meta-data from catalogues, but also deletes it from the storage backend.
The Veeam Plug-Ins provide a --set-force-delete option (e.g. Veeam Plug-In for SAP HANA) which forcefully deletes files from the backup repository after a given amount of days. It is recommended to configure this option and set it to a number of days outside of the own recovery window, to prevent any old and untracked files to consume storage space on the repository. This function is intended to work as a kind of garbage collector in case the normal retention process fails to delete files from the backup repository. If you backup to an immutable storage, make sure to configure this setting to a value higher than the immutability window to prevent error messages about undeletable files.
Windows network tuning
In larger environments lots of connections are made by the Plug-In backups. It is recommended to tune the network settings of the involved Windows machines in the Veeam infrastructure (Windows VBR server and Windows repository servers) according to the Microsoft guide to improve network performance:
-
Increase the available dynamic port range. The default dynamic ports range in Windows is 49152-65535 which is 16384 ports. Use the following command to increase the amount of available dynamic ports for IPv4 to 55525 without affecting ports of Veeam services:
netsh int ipv4 set dynamicport tcp start=10010 num=55525 -
Add
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\TcpTimedWaitDelayand set it to30to reduce the time a port keeps being blocked for reuse (default is 240 seconds)
Avoid OS TCP timeouts
The Veeam Plug-Ins will try to reach the configured Plug-In repository on all known IP addresses of the repository/gateway server. These IPs are sent to the Plug-In from the Veeam Backup & Replication server as a random list, like [192.168.1.10, 172.16.1.10, 10.0.1.10]. The Plug-In will try to connect to the Repository via these IPs and if an IP is not reachable, e.g. because a firewall drops the package or the IP is not routed but there is no info back to the source system, the OS will wait for the TCP RTO (retransmission timeout) to happen before reporting the destination as unreachable to the Plug-In. This process is repeated for every single file within a backup session.
E.g. on Linux the RTO timeout is 2 minutes (120s) by default. Every unanswered connection attemt will idle for 2 minutes before trying the next IP. So if you have 2 unreachable IPs to be tested before connecting on the right IP, every single file backup session will be delayed by 4 minutes.
Imagine a log file session with 2 files which might normally be finished within less than 30 seconds then taking 8 minutes (on one chanel) just because of the RTO timeouts per file.
In the following sequence you can see an example process of how the Plug-In connects to the repository. The example is a worst-case scenario where the to-be-used IP is the last in the list.
When a firewall drops a connection without notice the 2 minutes RTO timeout kicks in, when it denies the connection with a message the OS can directly mark the IP as unreachable instead:
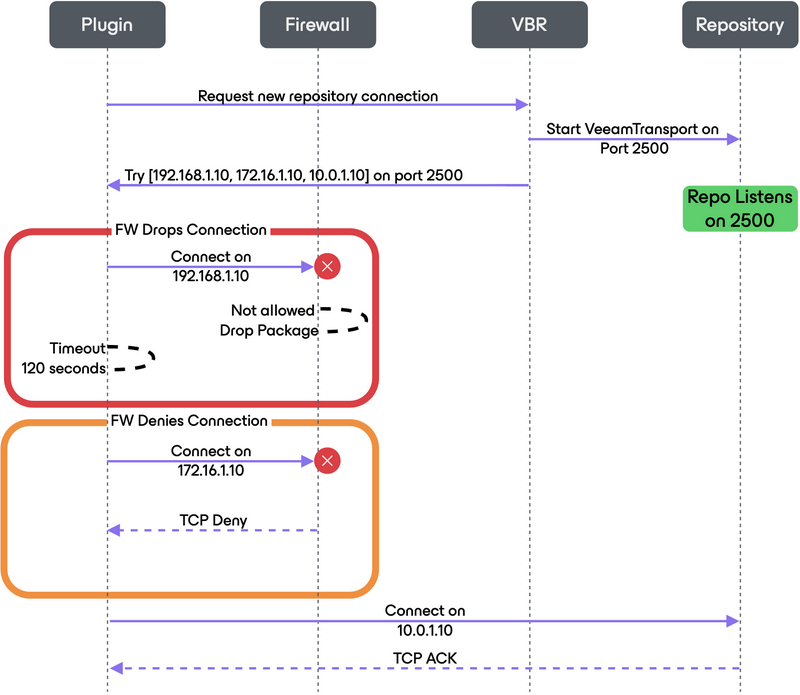
As best practice configure Veeam preferred network rules which modify the order of the returned repository IP list. IPs matching a preferred network will always be sorted to the beginning of the list, so the first connection attempt of the Plug-In will already be successful and prevent timeouts to delay your backups.
If preferred network rules can’t be used make sure that wrong connection attempts get a deny/unreachable answer. This can also be done by the local system’s firewall.
Resources
- Best Practice - Veeam Plug-In for Oracle RMAN
- Best Practice - Veeam Plug-In for SAP HANA
- Best Practice - Veeam Plug-In for Microsoft SQL Server
- Veeam Help Center - Enterprise Application Plug-Ins
- Windows Settings to be modified for improved network performance
- Veeam Help Center - Preferred Network Rules