



Veeam Backup & Replication Best Practice Guide
WAN Acceleration
Primary job mode affects the performance of backup copy job
Backup copy job works in forever incremental mode, transferring only the differences between previous and current job cycles to the target repository, no matter what type of the backup file is in the primary repository (Full or Incremental). WAN accelerator’s efficiency highly depends on the source job backup mode. Some backup methods result in a random I/O workload on the source repository (as opposed to sequential I/O patterns in other backup modes). Thus, the retrieval of needed blocks takes longer. The methods of reading from source is illustrated by the figure below:

As a result, Forward incremental and forever forward incremental methods will make backup copy jobs work much faster, as read operations will be sequential rather than random. These days, forward incremental is the most common backup mode anyway, but in case of a backup copy mode be aware of this behavior.
Though a workload penalty may not be significant, it can be a good idea to monitor the storage latency on the backup repository, especially if the reported bottleneck is ‘Source’. If the storage latency on the backup repository is high, it is recommended to change the backup mode in order to increase the throughput of one pair of WAN accelerators.
Other quick suggestions:
-
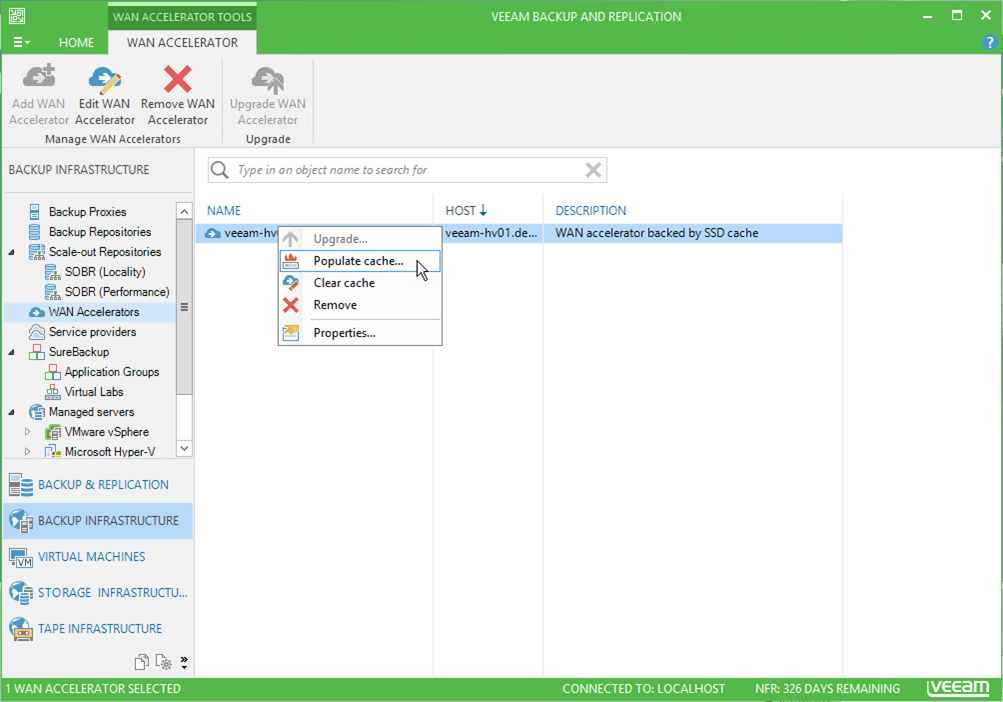
Once the target WAN accelerator is deployed, it is recommended to use the cache population feature. When using this feature, the WAN accelerator service will scan through selected repositories for protected operating system types.
-
It is also possible to seed the initial copy of data to the target repository to further reduce the amount of data that needs to be transferred during the first run.
How to read Job statistics
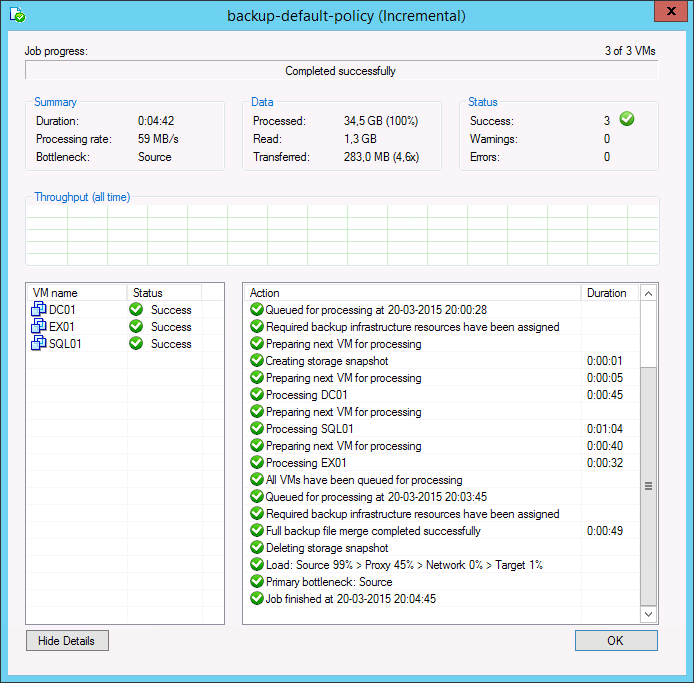
During both full and incremental job sessions, three metrics are displayed in the session data: Processed, Read and Transferred. To better understand the difference between direct data transfer and WAN accelerated mode, examine the Read and Transferred values:
-
Read— amount of data read from the production storage prior to applying any compression and deduplication. This is the amount of data that will be optimized by the WAN accelerator.
-
Transferred — amount of data written to the backup repository after applying compression and deduplication. This is the amount of data that will be processed by the backup copy job running in Direct Transfer mode (without WAN acceleration), assuming all VMs from the backup job are included in the backup copy job.