



Veeam Backup & Replication Best Practice Guide
SLA definition
In a data protection strategy, a service level agreement (SLA) is generally an understanding between the IT staff and the party it is servicing. This could be between departments within an enterprise, between a service provider and its client, and others.
The SLA should not only include a description of the services to be provided and their expected service levels, but also metrics by which the services are measured, the duties and responsibilities of each party, the remedies or penalties for breach and a protocol for adding and removing metrics.
The SLA should be a written document which is signed off by executive management. Otherwise it becomes a grey area, and in this case, IT teams often get blamed for undefined situations.
Functional requirements
To define the right data protection strategy, several input variables need to be taken into account. Besides the technical numbers, which we can measure with tooling, we need to define some functional requirements:
Backup
- Backup windows (e.g., what is the impact on the user’s experience, degraded system performance, etc.)
- Backup frequency (e.g., every hour, once a day, etc. and its feasibility and impact)
- Backup copies (e.g., to comply to 3-2-1 or other policies, regulations, ransomware protection)
Recovery
- Set specific timeframes for the data recovery based on the age of that data (e.g., data from yesterday restored from SAN will be faster than restoring 6-months old data from tape.)
- Define restore times (e.g., restoring a 500TB database with additional transaction log reply is going to take time)
- Restore guarantees (e.g., do we guarantee the latest copy of data? Within which timeframe? Checked for corruption? Where do we restore to? In which order do we restore? etc.)
Compliance and governance
- Classification of data (e.g., by importance or confidentiality, where to store backups?, etc.)
- Compliance (e.g., comply with local law regulations like EU GDPR, NIS2, NIST, specific audits, etc.)
- Governance (e.g., who has access to which data, encryption, etc.)
Next to the functional requirements, we also need to consider the impact of every possible scenario and to protect the business against disasters like:
- Ransomware attacks
- Hackers
- Data corruption
- Hardware failures
- Natural disasters (Fire, floods, storms, tsunamis, earthquakes, etc.)
Business continuity and disaster recovery plan (BCDR)
Two of the important parameters that define a BCDR plan are the Recovery Point Objective (RPO) and Recovery Time Objective (RTO):
-
RPO limits how far to roll back in time, and defines the maximum allowable amount of lost data measured in time from a failure occurrence to the last valid backup.
E.g. for a banking system, one hour of data loss can be catastrophic as they operate live transactions. At a personal level, you can also think about RPO as the moment you saved a document you are working on for the last time. In case your system crashes and your progress is lost, how much of your work are you willing to lose before it affects you? -
RTO is related to downtime and represents how long it takes to restore from the incident until normal operations are available to users.
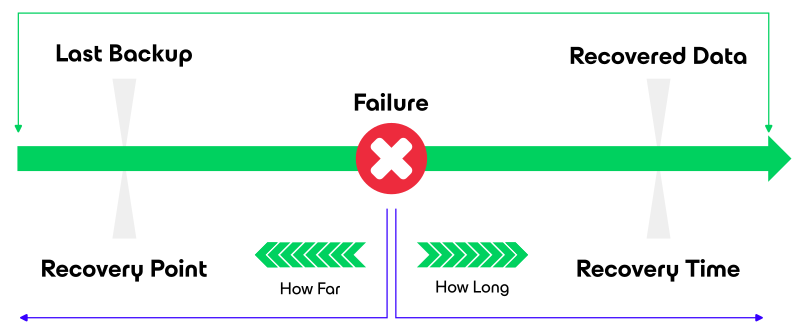
Define RTO and RPO values for your applications
The truth is there is no one-size-fits-all solution for a business continuity plan and its metrics. Companies are different from one vertical to another, have different needs, and therefore have different requirements for their recovery objectives. However, a common practice is to divide applications and services into different tiers and set recovery time and point objective (RTPO) values according to the service-level agreements (SLAs) the organization is committed to.
For example, you can use a three-tier model:
- Tier-1: Mission-critical applications that require an RTPO of less than 15 minutes
- Tier-2: Business-critical applications that require RTO of two hours and RPO of four hours
- Tier-3: Non-critical applications that require RTO of four hours and RPO of 24 hours
It’s important to keep in mind that mission-critical, business-critical and non-critical applications vary across industries and each organization defines these tiers based on their operations and requirements.