Veeam WAN Accelerator
By combining multiple technologies such as network compression, multi-threading, dynamic TCP window size, advanced deduplication and global caching, WAN acceleration provides increased transport speed for backup copy and replication jobs on low bandwidth or limited network links, or in any situation where we want to optimize the network usage at the expense of other components (cpu/memory/disk of the accelerators). This technology is specifically designed to accelerate Veeam jobs, and any other WAN acceleration technology should be disabled for Veeam traffic.
Veeam supports two operational modes of WAN accelerators:
- Low bandwidth mode, for the links with less than 100Mbps throughput
- High bandwidth mode, for high latency connections and specific cases described below The operational mode can be controlled in WAN accelerator properties.
| Bandwidth | Mode |
|---|---|
| 1-100 Mbps | Low bandwidth |
| Direct |
| Specific Case | High bandwidth |
Note that these values are the suggested operational limits of the WAN accelerator, or said differently, where the selected option performs at its best. Customers with no specific needs for bandwidth usage, or backup execution time, can also use direct connection with low bandwidth.
Low or High mode?
The main difference between the two modes is the use of the “global cache”, as High bandwidth mode does not use it. While High bandwidth mode operates similarly to Direct mode, it utilizes digest files (also used by Low bandwidth mode) to track changed data blocks. This additional filter allows the WAN accelerator to identify unchanged blocks during data processing between the source and destination, resulting in their exclusion from transfer, thus optimizing data transfer efficiency.
The efficiency of High bandwidth mode relies heavily on the amount of existing data changes and will not be as effective on new data, even with duplicate blocks. In such cases, its data reduction is comparable to that of Direct mode. High bandwidth mode demonstrates its advantages when dealing with workloads that experience a high daily change rate (more than 10%). Specifically, high-processing machines like database servers may benefit significantly from this mode, justifying the additional disk space and compute requirements.
Otherwise, High bandwidth mode may still be used with high bandwidth networks with high latency (more than 100ms), where direct mode is not efficient. In any other case, direct mode with high compression is recommended.
Note that High bandwidth mode puts more load on source than target.
WAN accelerator placement
WAN accelerators work in pairs: one WAN accelerator is deployed at the source site and another at the target site. Many to one scenario (e.g. ROBO-sites to a central site) is also possible but needs accurate sizing and has higher system requirements.
How many source WAN accelerators do I need?
Since WAN accelerator processes VM disks sequentially, you may consider using more than one source WAN accelerator on a single site to distribute tasks between them. Many-to-one scenario is supported; in this case, the target WAN accelerator should be sized carefully to be able to accept multiple incoming connection, and in general we recommend a maximum ratio of 4:1. Higher ratios are allowed in some specific situations, like many small links connecting to one large target WAN Accelerator; in this case we have observed ratio up to 20:1, but we suggest in this case to evaluate the design with a Veeam expert.
Mixed mode
If you are not sure about the mode you are going to use, or you plan for many-to-one scenario with various source modes, make sure you choose High-bandwidth mode during initial configuration of the target WAN accelerator settings. In such a case you will be able to work in both low and high bandwidth modes.
If you choose low bandwidth mode during the target configuration, WAN acceleration will process everything in low bandwidth mode only, despite of the source WAN accelerator settings.
Source WAN accelerator
System requirements for low and high bandwidth modes
The source WAN accelerator consumes a high amount of CPU and memory whilst re-applying the WAN optimized compression algorithm. The recommended system configuration is 4 CPU cores and 8GB RAM.
When you are using the WAN accelerator server also for other Veeam roles like proxy or repository, make sure not to overcommit CPU and memory resources and check that there are enough resources for each role. In general, we recommend to build machines where the WAN accelerator is the only Veeam role.
The I/O requirements for the source WAN accelerator spikes every time a new VM disk starts processing, so the typical I/O pattern is made of many small blocks. Thus, it is recommended to deploy WAN accelerators on disks with SSDs and avoid high latency spinning disks.
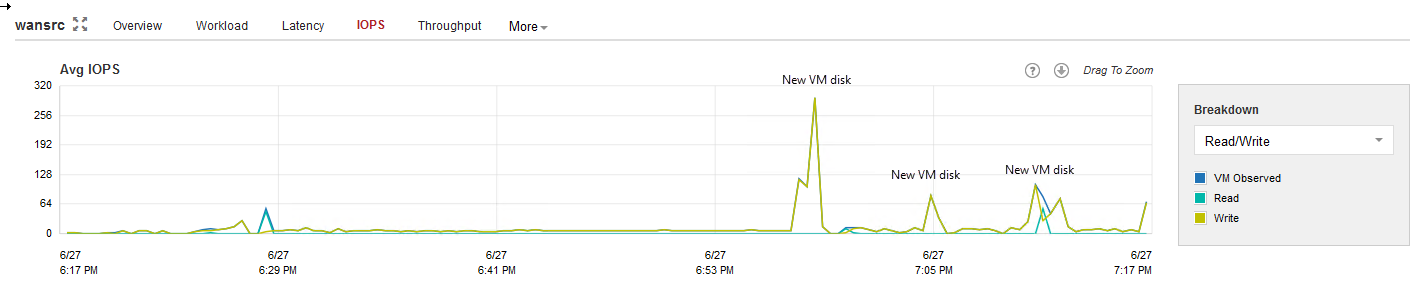 Source WAN accelerator IOPS
Source WAN accelerator IOPS
Sizing
Disk size
Source WAN accelerator stores only the digests of the processed VM OS data blocks in the VeeamWAN folder on the disk that you select when you configure the WAN accelerator. Disk digest file is created and placed in
\VeeamWAN\Digests\<JobId>_<VMId>_<DiskId>_<RestorePointID>
For more information about digest data sizing, please refer to the User Guide.
Note: The cache size setting in Low bandwidth on the source WAN accelerator will always be ignored, the digest files will be produced regardless of cache size setting configured. They may consume considerable disk space. Even if configuring the cache size on a source WAN accelerator is not as important, it still must exist as a number.
Another folder created on the source WAN accelerator working in Low bandwidth mode is the VeeamWAN\GlobalCache\src. The only file created in this directory is data.veeamdrf file. This file will be synchronized from the target WAN accelerator in following cases:
- Source WAN Accelerator cache was manually cleared, or digests deleted
- There was not enough space on the source WAN accelerator
- It is the first session after enabling the WAN accelerator setting
- If the job was seeded/mapped
The size of this file is typically up to 2% of the configured target cache size (see sizing target WAN); thus, it may take some time for the initial data transfer to begin
o Formula: data.veeamdrf = TargetCacheSize * 2%
Target WAN accelerator
System requirements
Low bandwidth mode
The following recommendations apply to configuring a target WAN accelerator.
Cache size
- The cache size setting configured on the target WAN accelerator will be applied per connected source WAN accelerator. This should be taken into account when sizing for many-to-one scenarios, as configuring 100GB cache size will result in 100GB multiplied by the number of source connections configured for each target WAN accelerator.
- It is recommended to configure the cache size at 10GB for each unique operating system processed by the WAN accelerator.
Note: Each version of Microsoft Windows OS is considered to be unique, while all Linux distributions are treated as one OS.
Although a target WAN accelerator consumes less CPU resources than the source, the I/O requirements for the target side are higher. For each processed data block, the WAN accelerator will update the cache file (if required), or it may retrieve the data block from the target repository (if possible). The cache is used only for blocks belonging to Operating Systems and Microsoft Exchange, all the other blocks are processed only with the WAN optimized data reduction algorithm.
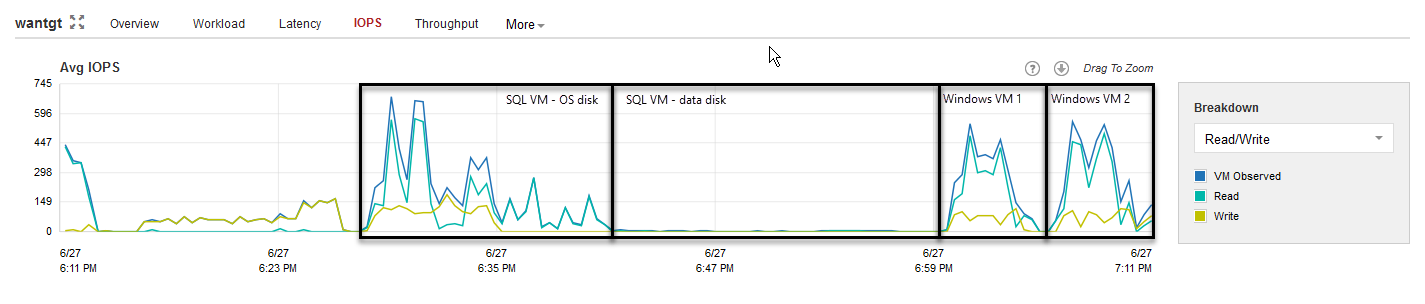 Target WAN accelerator IOPS
Target WAN accelerator IOPS
Tests show that there are no significant performance differences in using spinning disk drives as storage for the target WAN accelerator cache rather than flash storage. However, when multiple source WAN accelerators are connected to a single target WAN accelerator (many-to-one deployment), it is recommended to use SSD or equivalent storage for the target cache, as the I/O is now the sum of all the different sources.
High bandwidth mode
Since a target WAN accelerator utilizing only high bandwidth mode does not use global cache, neither it runs resource–intensive operations, it can be configured with at least four CPU cores and 8GB RAM as per the minimal system requirements.
By default, there is no permanent data stored on the target WAN accelerator working in high-bandwidth mode. However, in case of many-to-one scenario and mixed mode, please ensure that you have made calculations for all the low-bandwidth sources connected to the same target WAN accelerator.
It is possible that target WAN accelerator will require space for temporary storage of digest files. These cases include a manual clear cache operation on the source WAN accelerator, a corrupted digest file or other operations which require a re-calculation of the digest files. In these cases, the digest will be re-calculated from the target side data and the calculated digest file - which is 1- 2% of the source data - will be transferred to the source WAN accelerator and removed from target WAN accelerator afterwards.
o Formula: Digests max size = (Source data size in GB) * 2%
• Example: with 1 source 2TB source data: (2,000GB * 2 %)= 40GB
• Example: with 5 sources 2TB source data: (5*2,000GB * 2 %)= 200GB
Digest re-calculation on target will always be 2% of source data, if source WAN mode is low.
If working in a many to one scenario you should increase the CPU/RAM on target depending on the number of sources and source modes.
Sizing low-bandwidth mode
Disk size
Ensure that sufficient space has been allocated for global cache on the target WAN accelerator.
- Count at least 10GB per each different OS that is backed up.
- Plan for an additional 20GB of working space for cache population, payload and other temporary files.
- If the cache is pre-populated, an additional temporary cache is created. The temporary cache will be converted into the cache used for the first connected source. Subsequently connected sources will duplicate the cache of the first pair. As caches are duplicated the configured cache size is considered per pair of WAN accelerators.
Formulas:
• Formula for configured cache size (insert this number in configuration wizard):
o (Number of operating systems * 10GB) + 20GB
• Formula for used disk space (Many-to-one scenario)
o (Number of sources * <formula for configured cache size>)
Examples:
• Example with one source and two operating systems:
o Configured cache size: (2 operating systems * 10GB) + 20GB = 40GB
o Used disk space: (1 source * 40GB) = 40GB
• Example with five sources and four operating systems:
o Configured cache size: (4 operating systems * 10GB) + 20GB = 60GB
o Used disk space: (5 sources * 60GB) = 300GB
VeeamWAN\Digests
In some cases space for digest data is also required on the target WAN accelerator. These cases include a manually clear cache operation on the source WAN accelerator, a corrupted digest file or other operations which require a re-calculation of the digest cache.
In these cases the digest will be re-calculated from the target side data and the calculated digest file — which is 2% of the source data — will be transferred to the source WAN accelerator.
If the required 2% of source data is not available on the target side WAN accelerator the transport will continue in the limited mode which will not do any more deduplication.
• Example with 2TB of source data
o 2TB source * 2% = 40GB digest data
• Example with 5 sources each 2TB of source data
o 5 * 2TB source * 2% = 5 * 40GB = 200GB digest space
For understanding how the disk space is consumed, please see the following sections.
VeeamWAN\GlobalCache\trg
For each pair there will be a subfolder in the trg directory, with a UUID describing which source WAN accelerator the cache is attached to. In each of those subfolders, the blob.bin file containing the cache will be located. That file size corresponds to the setting configured in the management console.
Note: The blob.bin file will exist for all connected source WAN accelerators.
VeeamWAN\GlobalCache\temp
When connecting a new source WAN accelerator, the temp folder will temporarily contain the data.veeamdrf file that is later transferred to the source containing the cache manifest.