



Veeam Backup & Replication Best Practice Guide
These repositories provide a block storage device to a Windows or Linux server and can either be a local disk (=Direct Attached Storage) or a LUN provided by a SAN (Storage Area Network) via Fibre Channel or iSCSI.
Block size
During the backup process, data blocks are processed in chunks and stored inside backup files in the backup repository.
Veeam’s default block size is set to 1MB before compression. Since the compression ratio is very often around 2x, Veeam will write between 300-700KB on average per block to the backup repository. You can customize the block size in the job under Storage -> Advanced Settings -> Storage -> Storage optimization.
This value can then be used to better configure and align storage arrays. Generally, the optimal value for the stripe size is 128KB or 256KB if no specific recommendation is made by the hardware vendor. However, it is highly recommended to test this prior to deployment.
There are three layers where the block size can be configured:
- In Veeam
- On the file system
- On the storage volume
| Example with XFS as the underlying file system (=4KB block size) | Example with ReFS as the underlying file system (=64KB block size) |
|---|---|
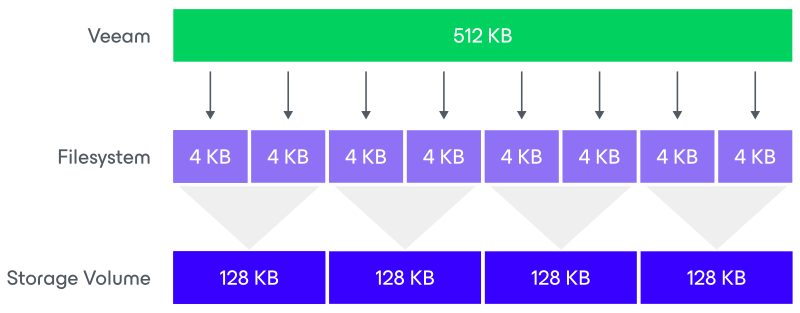 | 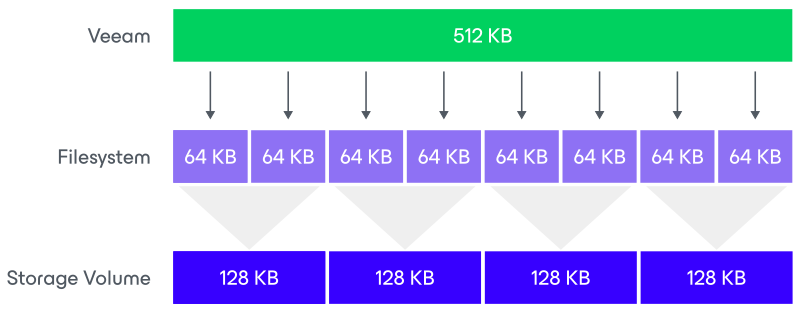 |
The Veeam block is going to be written in the underlying file system, which has a configured block size based on the type of file system that is used. It means that one block will consume several blocks at the file system level. No block will be wasted as the two are aligned. If possible, set the block size on the file system layer as close as possible to the expected Veeam block size.
Volume size
Our advise is to limit volume size to 500 TB and avoid filling it above 80 percent as this can cause performance drops.
This limit is not technical - as higher is definitely possible - but helps mitigating file systems failure domains and keep operations such as SOBR evacuation (e.g. migrations) or repository rescan more manageable. For example, the evacuation of a 500 TB SOBR extent at 1 GB/s read throughput would require approximately 6 days.
For larger Backup Repositories, bundle capacity by using a Scale-Out Backup Repository with multiple extents.
Important: One extent does not equal multiple volumes per physical backup repository. One extent means one physical server, containing one large volume. It is not recommended to have multiple extents per physical backup repository as this causes issues when scheduling tasks in VBR.
File Systems
Follow these general best practices when using either XFS or ReFS:
- Only use Windows Server Catalog certified hardware (contact your hardware vendor).
- Never use any shared LUN concept with ReFS and a Veeam Repository.
- Fully patched with the most recent Operating System updates.
XFS
Follow these best practices when using XFS:
- Format the volume with 4KB block size
- Follow the Fast Clone requirements for Linux Repositories.
- While XFS can scale up to very large amounts, always check the supported limits from your Linux vendor (e.g. RHEL8/9 support for XFS file systems is limited to 1PB) and consider other factors such as RAID rebuild and evacuation times when sizing your file system.
- Use LVM with XFS when you need more flexibility for volume management.
ReFS
Follow these best practices when using ReFS:
- Format the volume with 64KB block size
- Follow the Fast Clone requirements for Windows Repositories.
- Check the existing driver version of ReFS:
- The minimum should be
ReFS.sys 10.0.14393.2457on Windows Server 2016. - The minimum should be
ReFS.sys 10.0.17763.1369on Windows Server 2019.
- The minimum should be